![]() 4 juni, Westergasfabriek Amsterdam
800 bezoekers
4 juni, Westergasfabriek Amsterdam
800 bezoekers
Keynote - Spotify

Kristian Lindwall, Anders Ivarsson
Why?
Teams are called squads BFS, browse, feed, search Artist Team, x, y, z Together: music player Tribe
Spotify is made up out of Tribes
Interface elements are owned by different Tribes
All together an organic structure, people move toward other Tribes but stay connected to their original Tribe.
For a squad to be successful:
- Explore your context _ users and stakeholders _ priorities * interfaces (to the other squads)
- Deliver value - early and often _ squad and core metrics (engagement is also a metric, usage et cetera) _ prototyping (new running feature) * continuous delivery
- Keep improving _ improve everything _ retrospectives * embrace failure (fail wall, it’s not bad to fail, just accept it)
- Kickass engineering _ collective code ownership _ platformize (easy to deploy, easy to backup, automate) * automate everything
Leadership is about supporting the team Leadership is a behaviour, not a role
Agile coach [foto] 1700 personel, 25 coaches
Roles:
- Product owner
- Chapter (Team) lead -> “POTLAC”
- Agile coach
Strong leadership through team values
Forming, Storming, Norming and Performing model by Bruce Tuckman wikipedia
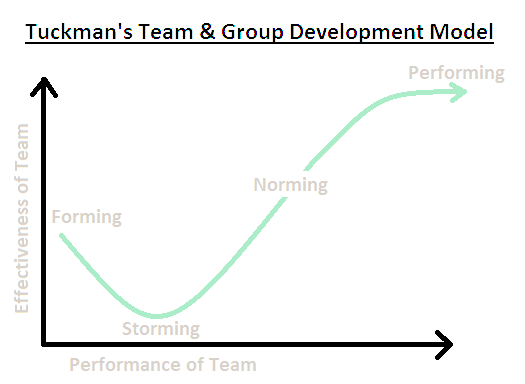
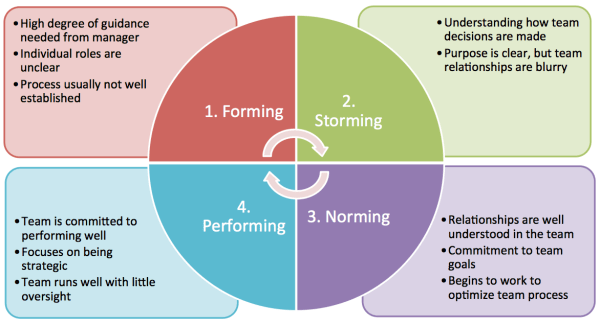
Understand the team, improve the values. Go for autonomy!
Autonomy vs Alignment
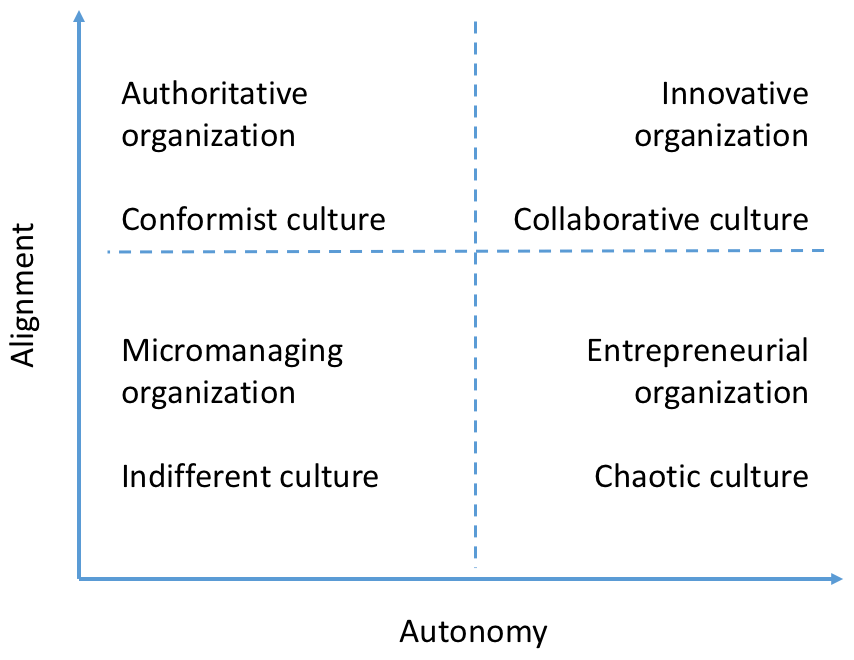
Hackweek, twice a year! 1700 people hacking. Results in new features like the running thing.
Strong autonomous team, with clear missions and supporting leadership
Go Data Driven NOW!
Friso van Vollenhoven, CTO of GoDataDriven @fzk frisovanvollenhoven@godatadriven.com Nice t-shirt (catching the cloud, Banksy)
Density plot on housing data, price per m^2
Which Meetup to sponsor, Graph visualized
Note to self: load connected LinkedIn members in to graph db, might be interesting.
Note to self: This only works if you know how to look at data
Google trends shows the interest of people Google Trends shows when it is full moon without really knowing it. Due to the searches. This is a good example of Big Data.
Hint: This only works if you put effort into the general availability of data.
Nobody understands Moore’s law. Almost a self-fulfilling prophecy, chip makers are aiming for it.
Compute power is getting cheaper Memory and Storage also gets cheaper
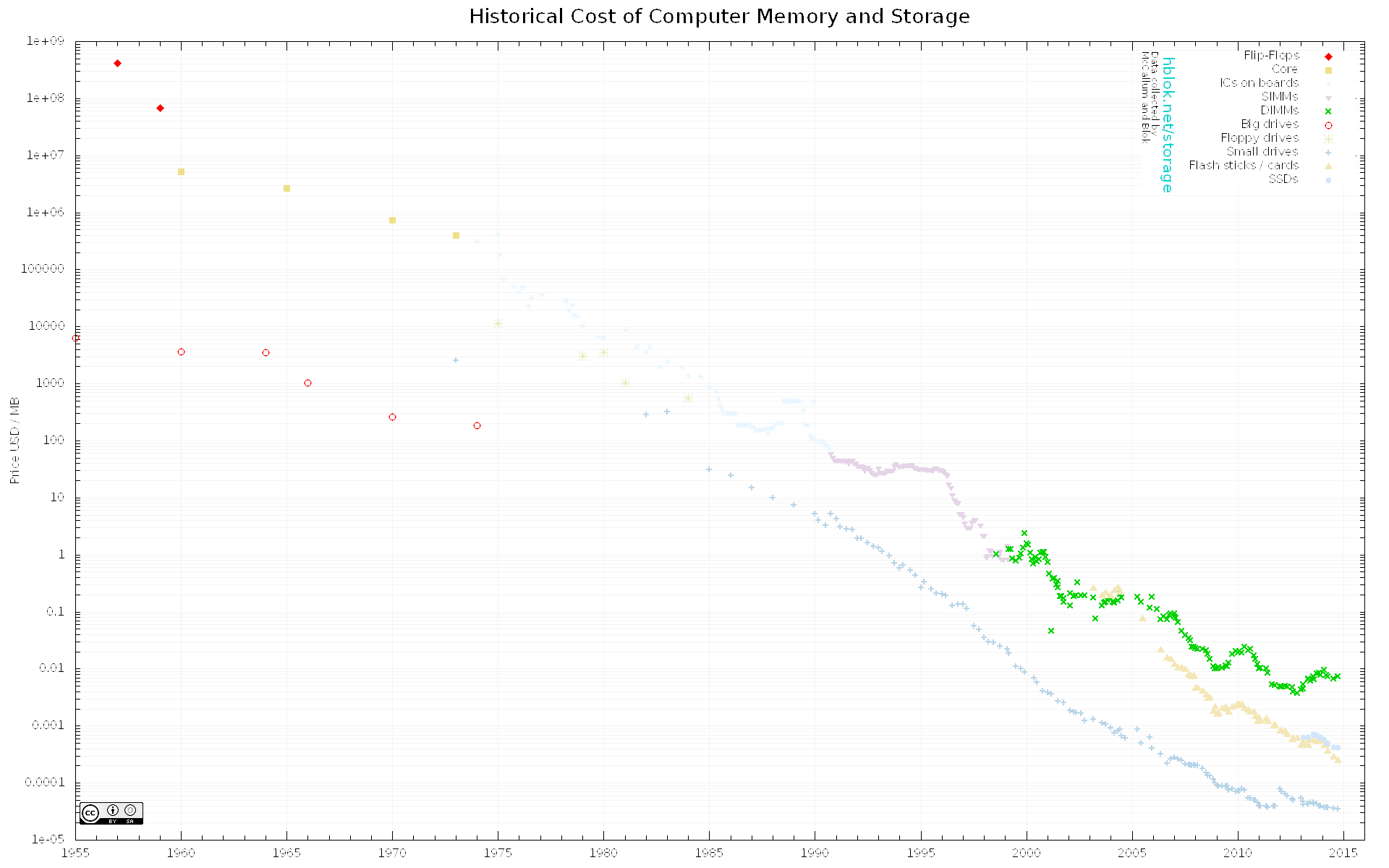 Historical Cost of Computer Memory and Storage
Where does the lead? Singularity? Prices are going to zero? Where does it end?
Historical Cost of Computer Memory and Storage
Where does the lead? Singularity? Prices are going to zero? Where does it end?
Hint: If hardware and licensing costs are part of your Big Data business cases, you’re working on the wrong cases in the wrong way.
Hint: In reality you need t think long and hard about problems and then still most experiments fail. Success lies in increasing the rate of experimentation / decreasing the cost of experimentation.
Whitepaper on marketing email from booking.com
Do you trust gut feeling over quantified priors?
“As a … I want …”, but what is the optimisation goal?
Note: Devmarketing, dev’s cooperate with the marketeers. Marketeers know what to look for, the dev know how to use the tooling.
If you generally make your data generally available … … and you can buy supercomputers for the price of a game compute … then the limiting factor is the maximum rate of experimentation.
Google paper: Machine Learning: The High Interest Credit Card of Technical Debt Abstract: Machine learning offers a fantastically powerful toolkit for building complex systems quickly. This paper argues that it is dangerous to think of these quick wins as coming for free. Using the framework of technical debt, we note that it is remarkably easy to incur massive ongoing maintenance costs at the system level when applying machine learning. The goal of this paper is highlight several machine learning specific risk factors and design patterns to be avoided or refactored where possible. These include boundary erosion, entanglement, hidden feedback loops, undeclared consumers, data dependencies, changes in the external world, and a variety of system-level anti-patterns.
The final question: Do you have an experimentation framework?
Deploying twice at Kadaster
Raymond Kroon, Software Engineer
- My first fix: write once run everywhere
- No linux dev machine, not at Kadaster
- Buildserver
- Data Processing
- Multiple data in formats
- Multiple delivery methods
- Data transformations
Automation try #1 with ETL failed
Fixes:
- Simple custom linear workflow
Code vs Tool (Clojure) 3000 lines vs 50 lines
Clojure made for data transformations?
Lessons learned:
- Would I do it again?
- Did I make a difference?
- Can any team do it?
Beyond Single Page Applications with Isomorphism
Gert Hengeveld, Full Stack Developer at Xebia @ghengeveld
Web Application Evolution

Note: While looking for an image I found The Evolution of the Web an interactive version of the image below.
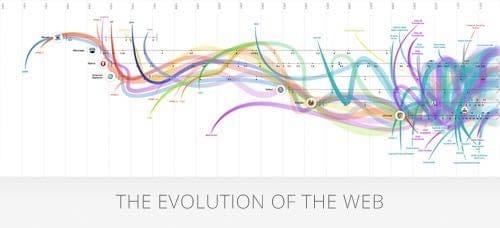
History of building webpages (top to bottom, from server to client):
- Classic web pages
- JavaScript enhancements
- Isomorphic applications (the sweet spot)
- Single-page applications
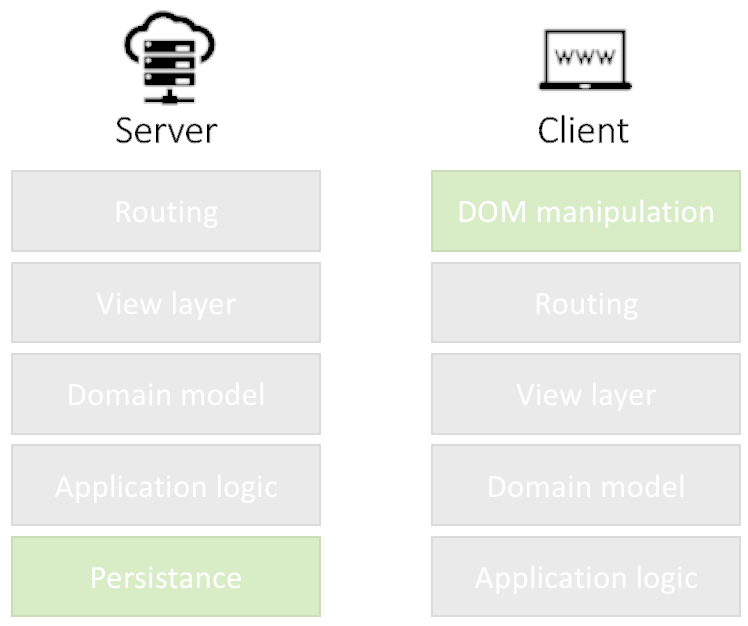
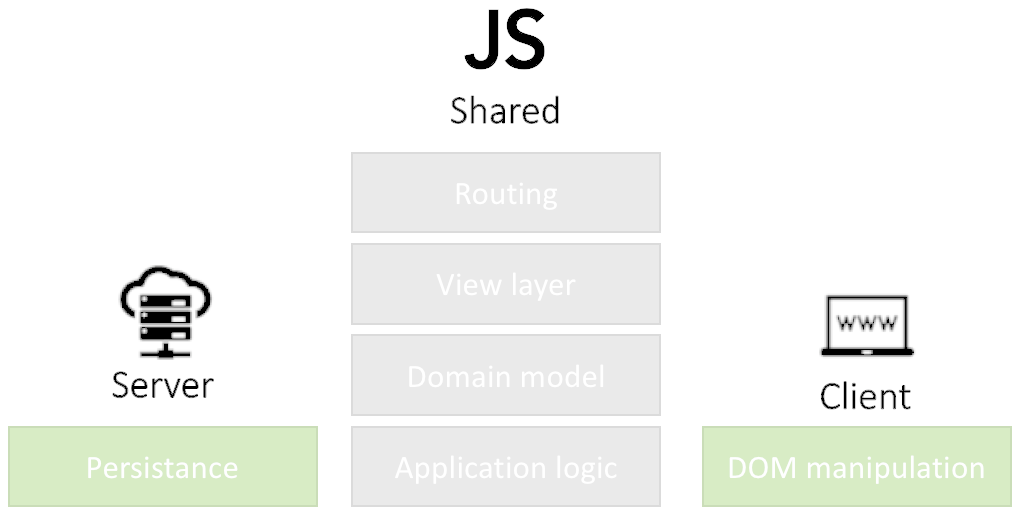
Isomorphic applications can fallback to the server to solve (render) problems at serverside.
Isomorphic applications are single-page applications that don’t break the web Initial state is rendered by he server then the browser takes over
Not every client has JavaScript enabled or available:
- 1.1 percent of the users don’t 1 - Corporate or local blocking/modification - Existing errors in the browser - Network errors
- Machines mostly don’t
Speed matters
- lost focus after 1 second
- 57% will leave after 3 seconds 2
- Factor in Google ranking
- Wider range of devices
- Unreliable connections
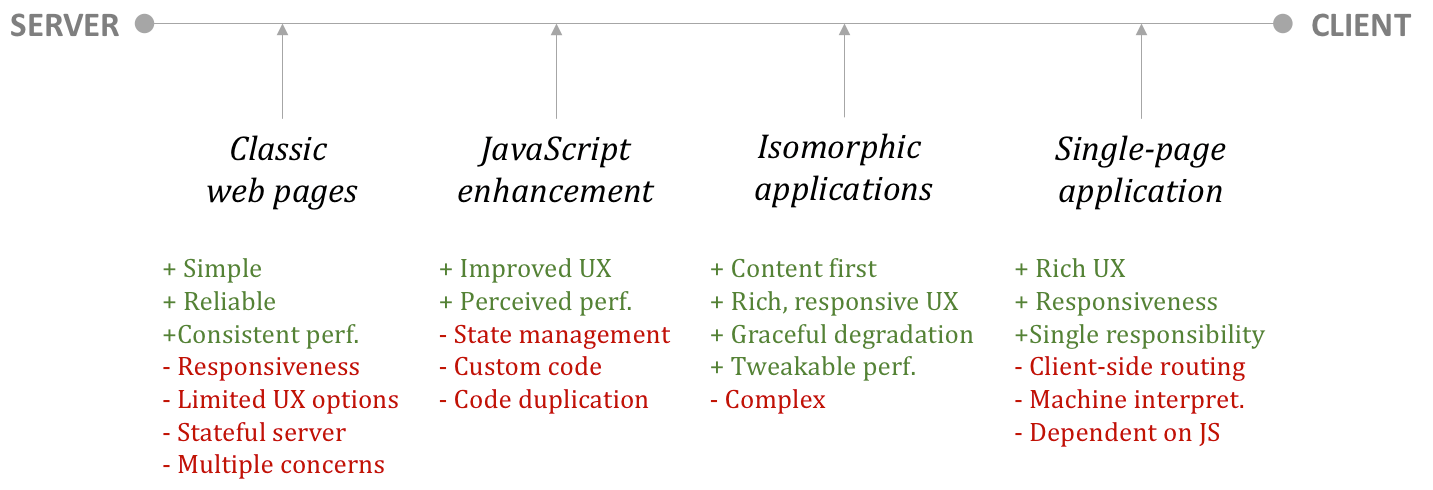
Technical implications
- Two codebases * Logic implemented twice
- Isomorphic JavaScript * Same code, multiple environments
Two levels of isomorphism:
- Functional, Isomorphic rendering
- Technical, Isomorphic codebase
- Isomorphic JavaScript (or anything that compiles into JavaScript)
Tessel, IoT board that runs JavaScript natively
Isomorphic JavaScript is environment-agnostic or provides a common API
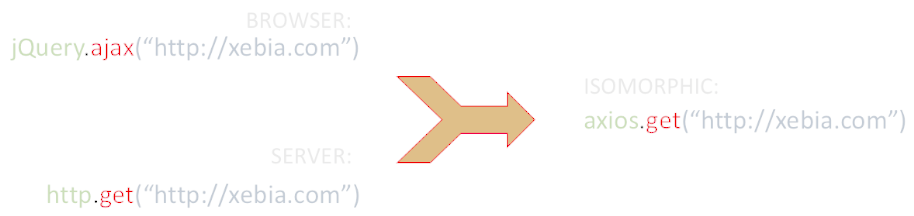
Isomorphic stack:
- Handling HTTP requests (Superagent, Axios)
- URL routing (Director from the flatiron framework, react-router)
- View rendering (React, Handlebars, FormatJS)
- Module loading (Browserify, Webpack)
Isomorphic frameworks:
- Rendr (Airbnb)
- Ember (fastboot, add-on to provide Isomorphism)
- Meteor (very complete)
- Este.js
- Taunus
- Lazojs
- Derby
Do you need Isomorphism?
- Content focused? Yes
- Productivity focused? Maybe
Expectation is that in two years most frameworks provide isomorphism
Beyond isomorphism:
An adaptive web application constantly monitors and adapts itself to changing conditions, switching back to server-side rendering if necessary.
Building Hyper-Scale Platform-as-a-Service Microservices with Microsoft Azure
Patriek van Dorp en Alex Thissen
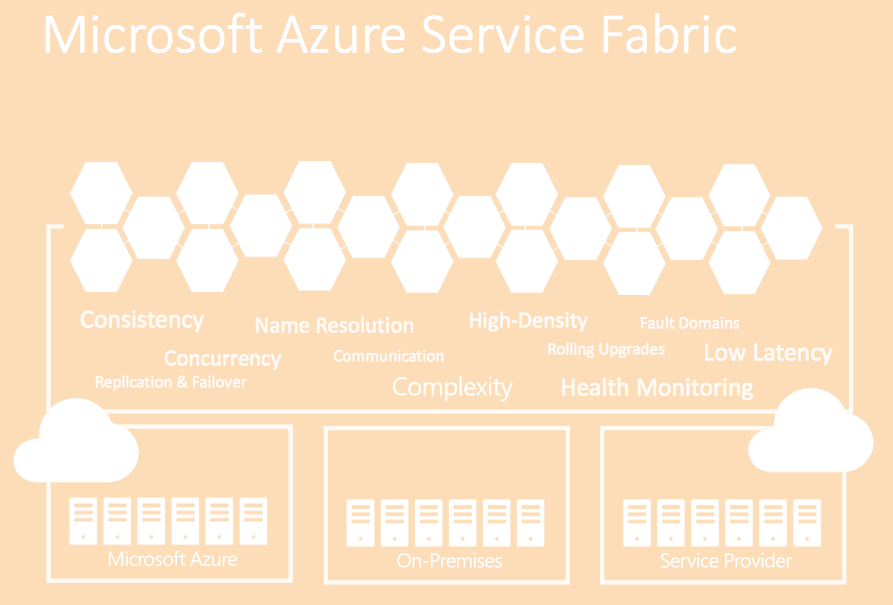
What can you build with Service Fabric:
- Stateless Microservices: - Has no local persistent state - Optionally stores state in external data stores - Can have multiple instances for improving performance - e.g. Web API, Gateway Service, et cetera
- Stateful Microservices: - Contain highly consistent local state - Provides redundancy through replication - Scale for performance, not for redundancy - e.g. Database, Workflows, et cetera
- Existing apps written with other frameworks - Node.js, Java VMs any EXE
Actor-model API
Project “Orleans” invented the Virtual Actor abstraction. Orleans provides a straightforward approach to building distributed interactive applications, without the need to learn complex programming patterns for handling concurrency, fault tolerance, and resource management. Orleans applications scale-up automatically and are meant to be deployed in the cloud. Halo (the Game) uses it as backend.
Reliable actors:
- Actors are isolated single-threaded components that encapsulate both state and behaviour
- Actors communicate with the system, including other Actors, by sending asynchronous messages with a request/response pattern.
- Actors are virtual there is no need to initialise or destroy them.
Summary
- Microservices as a potential architecture style
- Adding complexity to gain simplicity
- Choose an appropriate programming model
- Azure platform services help solve remaining challenges for reliability and scaling
The 24 man DevOps team
Serge Beamont, Agile Consulant Xebia
My First Principle of Scaling: Autonomy over Coordination (A > C)

Partitioning into autonomous groups reduces complexity
Each cell should have an autonomous product identity “Is your identity your function or product?”
The Definition of Done defines the skill mix
Partitioning Rules:
- Sized to human communications (5-9)
- Autonomous Product Identity
- DoD defines the skill mix
- Distribute skills evenly (after DoD rule)
Autonomy reduces complexity
First maximize autonomy, coordinate that what is left behind
One backlog “To Rule Them All”: one overall product identity
Divide the whole, don’t connect loose cells
Good tribes have internal flexibility
It’s only DevOps when the devs have pagers!
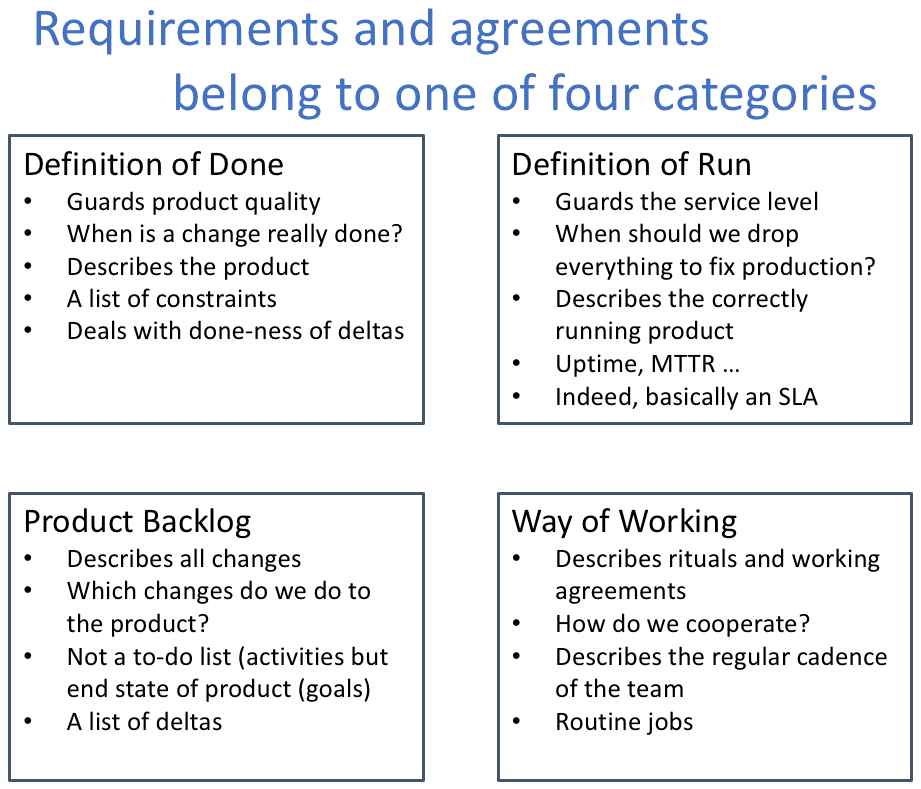
Requirements and agreements belong to one of four categories:
- Definition of Done
- Backlog
- Definition of Run
- Way of Working
Constant velocity assumes constant team cadence: watch it!
The most autonomy is achieved with a Snowman architecture, formal name Vertically Aligned Synergistically Partitioned (VASP) Architecture (Roger Sessions).
Are autonomy and XaaS contradictions? “Let’s connect it all with a Platform! => “You al depend on the Platform Team now!”
Owning the code is not the same as owning the production instance:
- Platform Team: Owns the platform code not a running instance
- DevOps Team: Owns the running instance not the platform code
XaaS without true self-service is a failure:
- Platform Team: You want a platform instance? Put in a service request!
- DevOps Team: Dudes srsly? Just give us the Platform Product!

Automatic Docker Deployments with Marathon
Michael Hausenblas, Datacenter Application Architect, @mhausenblas, michael.hausenblas@mesosphere.io
Architecture:
- Docker
- Mesos-DNS
- Marathon
- Mesos
- Redis
- Nginx
- Kibana
- Logstash
- Elasticsearch
- Mesosphere

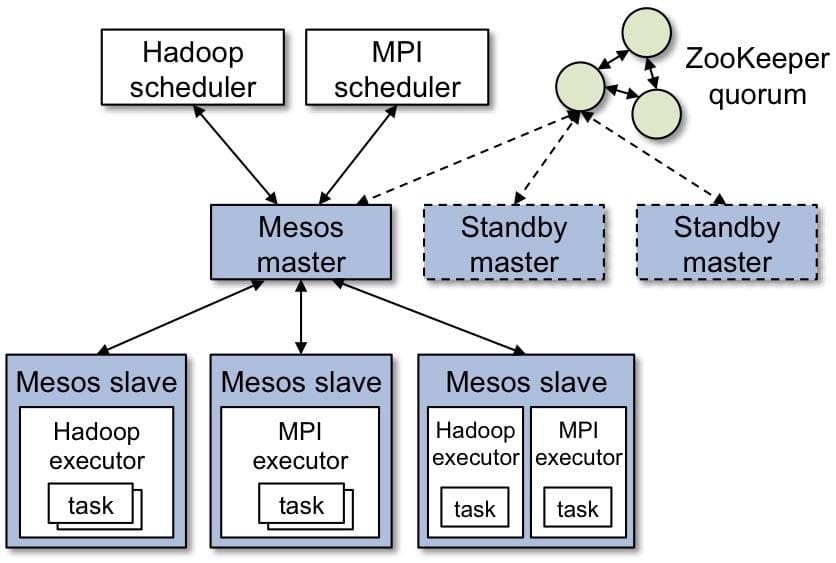
Apache Mesos, two way scheduler
 Marathon:
Marathon:
- Long-running tasks
- Docker support
- HTTP API
- HA, health checks, groups, scaling
Mesos-DNS, standard Go-based application
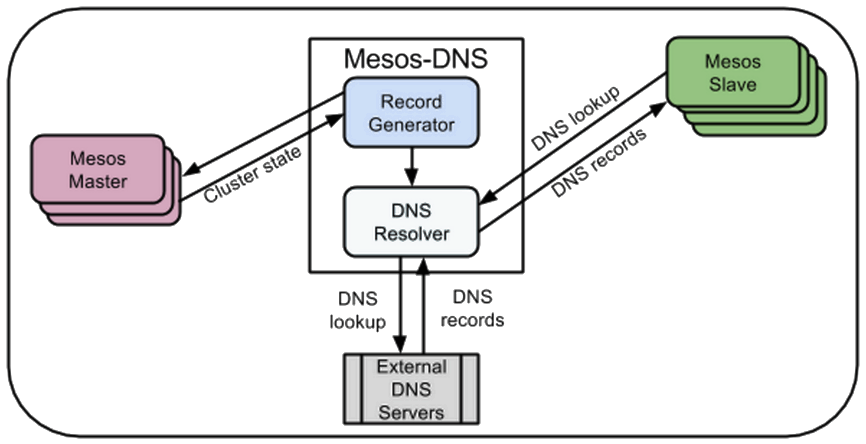
Github mhausenblas/mc
CORS problem solvable by adding a reverse proxy/DNS? fluentd
Best practices:
- Make no assumptions, because everything that can fail, will fail
- Pets vs Cattle blogpost
- Service Discovery (Mesos-DNS + JS)
- Private Docker repo
DCOS
Uses DCOS as basis
Wrapping up …
- Use Marathon for Docker container orchestration
- Remember: cattle herding!
- Try out the DCOS: https://mesosphere.com/product/ Mail Michael to get the bits earlier
- We’re hiring: https://mesosphere.com/careers/

Building the World’s Largest Websites with Consul and Terraform
Mitchell Hashimoto, HashiCorp, @mitchellh
 DC Evolution, challenges of the modern datacenter:
Rising DC complexity, more metal, more VMs, noisy neighbours, VMs with containers. IaaS, SaaS, PaaS. Different OSes Win, Mac, Linux.
DC Evolution, challenges of the modern datacenter:
Rising DC complexity, more metal, more VMs, noisy neighbours, VMs with containers. IaaS, SaaS, PaaS. Different OSes Win, Mac, Linux.
More and more services are moving outside our DC. We have to get comfortable with that idea.
Consul, consul.io, Service discovery, self-healing
Quests that Consul Answers:
- Where is the service foo?
- What is the health status of service foo?
- What is the health status of the machine/node foo?
- What is the list of all currently running machines?
- What is the configuration of service foo? Is anyone else cruelty performing operation foo?
Terraform, codify platform knowledge
Scalabilty, Resiliency, Determinism
Scalability:
- Expectation of high QPS per resource
- CPU, memory are valuable resources
- One less server for utility = one more server for serving customers
- Push vs. Pull, a.k.a. Edge triggered changes
Resiliency:
- Probability of failure goes up for scale
- Embrace failure and make it acceptable
- Constant change at some scale
- Self-healing systems become much more important (automatic anti-entropy)
- Central sources of truth become liabilities
Determinism:
- Understand the full effect of a change
- Predictable (but not necessarily strict) ordering of a change
- Limiting surprises that can cause downtime
Traditional Service Configuration: Pull-based, long intervals, computationally expensive Consul K/V + Consul-Template: Push-based, “instant”, predictable computational cost
Consul, much faster
Consul + Terraform used in large platforms: Twitch, Square, AOL, large banks (not to be named)
Step by step:
- Config management puts down configuration template
- Consul-template runs as a service
- Edge triggers config changes, restarts service
Zero TTL DNS:
- Long-held connections to minimise DNS overhead
- Zero TTL ensures most up-to-date information
Resiliency:
- Low-TTL DNS records
- Ensures availability even if Consul is unavailable
- Required for short-held connections since DNS lookup overhead is too high with zero TTL
Consul can be overloaded, set low TTL, stale reads on non… Three options:
- Consul settings. Per service, stale reads on non-leaders
- DNSMASQ + Consul. Global, works if Consul is down
- Application-Level Cache. Works if almost everything is down, strict control over cache times
First two options should get you covered

dnsmasq is a free software DNS forwarder and DHCP server for small networks. It is considered to be easily configured, with low system resource usage (wikipedia).
Traditional monitoring
Consul removes unhealthy nodes from the service discovery layer Only changes are sent by the Agents
Atlas is the commercial offering, includes notifications
Consul distributed locking, network semaphore Ensure “at most N” tasks
Consul events, edge triggered, uses UDP Watch, Execute
Terraform Plan, missing from Heat or other Cloud Management Platforms
Terraform Graph
Terraform Modules, Remote State (Unit of resource sharing)
Terraform Service Composition, connecting multiple service providers
Logical Resources, thinking in Graphs
History of Infrastructure Change via Atlas (commercial):
- Who, did what, how
- Treat infrastructure as an application
Interview via InfoQ: Mitchell Hashimoto on Consul, Terraform, Atlas, Go as a Language for Tools (best watched with Chrome, Safari doesn’t show the video)
Mindf*ck
Victor Mids, Illusionist and Doctor @victormids
“Red Hammer” statistical guess, obfuscated by the sum’s, primal tasks take over.
Neuromagic, remember free choice and what is supposed to be the “truth”. Is it your truth or is it their truth. What “truth” is shown. Remember the “trick”, it’s not said how it is going to be presented, giving the performer a chance to show you his “truth”.
Pick an envelope, #1, #2 or #3 - three times a different truth:
- all with papers inside (#1 a cross, #2 a cross, #3 this is the one)
- all written on the backside (#1 a cross, # this is the one, #3 a cross)
- and a fallback notebook displaying the third option (“you have chosen envelope #1 …")
Interesting links
Xebicon event site
Xebicon event site Videos and slides of the event.
Hands-On Golang:

download from http://bit.ly/1M7ArDj or https://github.com/MarcGrol/go-training
apply(Scala)
Pakhuis De Zwijger, Amsterdam 8 oktober 2015 #1 day University sessions 9 oktober 2015 #1 day Conference applyconf.com
Next, a Google Cloud Platform Experience
25 juni 2015, Westergasfabriek, Amsterdam registratie
Open Kitchen - Xebia
Utrechtseweg 49, Hilversum Open Kitchen events