Configuration Management Camp is the event for technologists interested Open Source Infrastructure automation and related topics. This includes but is not limited to top Open Source Configuration Management, Provisioning, Orchestration, Choreography, Container Operations, and many more topics.
![]()
Untitled Config Game
Ryn Daniels | they/them | @rynchantress
Title refers to the Untitled Goose Game where you are horrible goose.

State
- Application state
- System state
- Configuration state
- Source state
- Human state
horrible lessons learned
- Don’t forget about application state
- Knons aren’t always known
- Monitor your configuration state
- Don’t leave your states unsupervised
- Enforce source state completeness and config state consistency
- Get rid of unreliable tools
- Make sure your tooling is usable by humans
“Make it hard to do the wrong thing”
Cobbler

Cobbler is a Linux installation server that allows for rapid setup of network installation environments. It glues together and automates many associated Linux tasks so you do not have to hop between many various commands and applications when deploying new systems, and, in some cases, changing existing ones. Cobbler can help with provisioning, managing DNS and DHCP, package updates, power management, configuration management orchestration, and much more.
Can TypeScript really make infrastructure management easy?
Paul Stack | Pulumi
In this talk, Paul will demonstrate why TypeScript is a great language of choice for infrastructure management. Pulumi is an open source tool that allows users to write their infrastructure code in TypeScript, Python or Go.
TypeScript allows infrastructure code to have integrated testing, compile time checks as well as being able to create infrastructure APIs. This will show why a real language is more suited to infrastructure management than DSLs, JSON or YAML. In addition, he will cover how to build infrastructure that manages Serverless, PaaS and IaaS systems across multiple cloud providers.
Pulumi “sales-pitch” but still a force to be reckoned with. Like Terraform but more polyglot.
Pulumi

Pulumi is an open source infrastructure as code tool for creating, deploying, and managing cloud infrastructure. Pulumi works with traditional infrastructure like VMs, networks, and databases, in addition to modern architectures, including containers, Kubernetes clusters, and serverless functions. Pulumi supports dozens of public, private, and hybrid cloud service providers.
Configuration Management in 2020 and Beyond
Eric Sorenson | Puppet
The Twelve-Factor App
The twelve-factor app is a methodology for building software-as-a-service apps that:
- Use declarative formats for setup automation, to minimize time and cost for new developers joining the project;
- Have a clean contract with the underlying operating system, offering maximum portability between execution environments;
- Are suitable for deployment on modern cloud platforms, obviating the need for servers and systems administration;
- Minimize divergence between development and production, enabling continuous deployment for maximum agility;
- And can scale up without significant changes to tooling, architecture, or development practices.
The twelve-factor methodology can be applied to apps written in any programming language, and which use any combination of backing services (database, queue, memory cache, etc).
- Codebase - One codebase tracked in revision control, many deploys
- Dependencies - Explicitly declare and isolate dependencies
- Config - Store config in the environment
- Backing services - Treat backing services as attached resources
- Build, release, run - Strictly separate build and run stages
- Processes - Execute the app as one or more stateless processes
- Port binding - Export services via port binding
- Concurrency - Scale out via the process model
- Disposability - Maximize robustness with fast startup and graceful shutdown
- Dev/prod parity - Keep development, staging, and production as similar as possible
- Logs, Treat logs as event streams
- Admin processes - Run admin/management tasks as one-off processes
*lities
- Ephemerality
- Cardinality
- Immutability
- Data…bility
Declarative …
“an agent on a system that can alter the state is a no-go”, Eric Sorenson
From Pets to … to Insects
The Pets vs Cattle analogy is wellknown, but it seems this does not cover all services we have nowadays. In this session the speaker mentioned Pets vs Cattle vs Insects but Russ McKendrick’s post The pets and cattle analogy demonstrates how serverless fits into the software infrastructure landscape gives a nice overview.

From Russ’s post:
- Pets, bare metal machines and virtual machines
- Cattle, instances you run on public clouds
- Chickens, an analogy of containers
- Insects, an anlogy of serverless/functions
I would like to put it more stricly:
- Pets, bare metal machines
- Cattle, virtual machines
- Chickens, containers
- Insects, serverless/functions
And you can always pet your chicken …
Other exceptions are the Snowflakes. These are unique, impossible to reproduce and delicate machines.
Summing it up:
Organizations who have pets are slowly moving their infrastructure to be more like cattle. Those who are already running their infrastructure as cattle are moving towards chickens to get the most out of their resources. Those running chickens are going to be looking at how much work is involved in moving their application to run as insects by completely decoupling their application into individually executable components.
But the most important take away is this:
No one wants to or should be running snowflakes.
Infrastructure as …
- Infrastructure as code
- Infrastructure as software
- Infrastructure as data
Kelsey Hightower on Extending Kubernetes, Event-Driven Architecture, and Learning
The Configuration Complexity Clock
Code Rant blog: The Configuration Complexity Clock
When I was a young coder, just starting out in the big scary world of enterprise software, an older, far more experienced chap gave me a stern warning about hard coding values in my software. “They will have to change at some point, and you don’t want to recompile and redeploy your application just to change the VAT tax rate.” I took this advice to heart and soon every value that my application needed was loaded from a huge .ini file. I still think it’s good advice, but be warned, like most things in software, it’s good advice up to a point. Beyond that point lies pain.
Let me introduce you to my ‘Configuration Complexity Clock’.
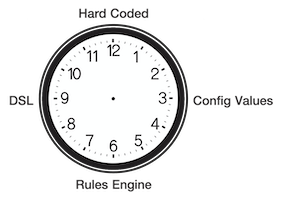
This clock tells a story. We start at midnight, 12 o’clock, with a simple new requirement which we quickly code up as a little application. It’s not expected to last very long, just a stop-gap in some larger strategic scheme, so we’ve hard-coded all the application’s values. Months pass, the application becomes widely used, but there’s a problem, some of the business values change, so we find ourselves rebuilding and re-deploying it just to change a few numbers. This is obviously wrong. The solution is simple, we’ll move those values out into a configuration file, maybe some appsettings in our App.config. Now we’re at 2 on the clock.
Time passes and our application is now somewhat entrenched in our organisation. The business continues to evolve and as it does, more values are moved to our configuration file. Now appsettings are no longer sufficient, we have groups of values and hierarchies of values. If we’re good, by now we will have moved our configuration into a dedicated XML schema that gets de-serialized into a configuration model. If we’re not so good we might have shoe-horned repeated and multi-dimensional values into some strange tilda and pipe separated strings. Now we’re at 4 or 5 on the clock.
More time passes, the irritating ‘chief software architect’ has been sacked and our little application is now core to our organisation. The business rules become more complex and so does our configuration. In fact there’s now a considerable learning curve before a new hire can successfully carry out a deployment. One of our new hires is a very clever chap, he’s seen this situation before. “What we need is a business rules engine” he declares. Now this looks promising. The configuration moves from its XML file into a database and has its own specialised GUI. Initially there was hope that non-technical business users would be able to use the GUI to configure the application, but that turned out to be a false hope; the mapping of business rules into the engine requires a level of expertise that only some members of the development team possess. We’re now at 6 on the clock.
Frustratingly there are still some business requirements that can’t be configured using the new rules engine. Some logical conditions simply aren’t configurable using its GUI, and so the application has to be re-coded and re-deployed for some scenarios. Help is at hand, someone on the team reads Ayende’s DSLs book. Yes, a DSL will allow us to write arbitrarily complex rules and solve all our problems. The team stops work for several months to implement the DSL. It’s a considerable technical accomplishment when it’s completed and everyone takes a well earned break. Surely this will mean the end of arbitrary hard-coded business logic? It’s now 9am on the clock.
Amazingly it works. Several months go by without any changes being needed in the core application. The team spend most of their time writing code in the new DSL. After some embarrassing episodes, they now go through a complete release cycle before deploying any new DSL code. The DSL text files are version controlled and each release goes through regression testing before being deployed. Debugging the DSL code is difficult, there’s little tooling support, they simply don’t have the resources to build an IDE or a ReSharper for their new little language. As the DSL code gets more complex they also start to miss being able to write object-oriented software. Some of the team have started to work on a unit testing framework in their spare time.
In the pub after work someone quips, “we’re back where we started four years ago, hard coding everything, except now in a much crappier language.”
They’ve gone around the clock and are back at 12.
Why tell this story? To be honest, I’ve never seen an organisation go all the way around the clock, but I’ve seen plenty that have got to 5, 6, or 7 and feel considerable pain. My point is this:
At a certain level of complexity, hard-coding a solution may be the least evil option.
You already have a general purpose programming language, before you go down the route of building a business rules engine or a DSL, or even if your configuration passes a certain level of complexity, consider that with a slicker build-test-deploy cycle, it might be far simpler just to hard code it.
As you go clockwise around the clock, the technical implementation becomes successively more complex. Building a good rules engine is hard, writing a DSL is harder still. Each extra hour you travel clockwise will lead to more complex software with more bugs and a harder learning curve for any new hires. The more complex the configuration, the more control and testing it will need before deployment. Soon enough you’ll find that there’s little difference in the length of time it takes between changing a line of code and changing a line of configuration. Rather than a commonly available skill, such as coding C#, you find that your organisation relies on a very rare skill: understanding your rules engine or DSL.
I’m not saying that it’s never appropriate to implement complex configuration, a rules-engine or a DSL, Indeed I would jump at the chance of building a DSL given the right requirements, but I am saying that you should understand the implications and recognise where you are on the clock before you go down that route.
kapitan
![]()
Kapitan is a tool to manage complex deployments using jsonnet, kadet (alpha) and jinja2.
Use Kapitan to manage your Kubernetes manifests, your documentation, your Terraform configuration or even simplify your scripts.
How it is different from Helm? In short, we feel Helm is trying to be apt-get for Kubernetes charts, while we are trying to take you further than that. Read the FAQ for more details on the differences.
kr8
kr8 is a configuration management tool for Kubernetes clusters, designed to generate deployable manifests for the components required to make your clusters usable.
Its main function is to manipulate JSON and YAML without using a templating engine. It does this using jsonnet
Lee Briggs blog: Multi-Cluster Parameterized Continuous Deployment for Kubernetes)
Tanka

Tanka Tanka is a composable configuration utility for Kubernetes. It leverages the Jsonnet language to realize flexible, reusable and concise configuration.
Highlights:
- Flexible: The Jsonnet data templating language gives us much smarter ways to express our Kubernetes configuration than YAML does.
- Reusable: Code can be refactored into libraries, they can be imported wherever you like and even shared on GitHub!
- Concise: Using the Kubernetes library and abstraction, you will never see boilerplate again!
- Work with confidence:
tk diffallows to check all changes before they will be applied. Stop guessing and make sure it’s all good. - Used in production: While still a very young project, Tanka is used internally at Grafana Labs for all of their Kubernetes configuration needs.
- Fully open source: This is an open-source project. It is free as in beer and as in speech and this will never change.
Magic YAML
Julien Pivotto | Inuits
Great short session on YAML do’s and dont’s.
YAML
YAML may seem ‘simple’ and ‘obvious’ when glancing at a basic example, but turns out it’s not.
- YAML enables you to have multiple documents in one file
- There are nine ways to write a multi-line string in YAML with subtly different behaviour
- Version number 3.5.3 gets recognized as as string, but 9.3 gets recognized as a number instead of a string
- With the YAML 1.1 spec, there are 22 options to write “true” or “false.”. Abbreviating Norway to NO is one of them.
Arp242’s blog post provides a nice overview and there is noyaml.com for the real fans.
TOML is a good alternative or use the StrictYAML parser for a safer restricted subset.
Serverless
What idiot called it serverless and not “The Emperor’s New Servers”

From Build scalable APIs using Kong and OpenWhisk:
Serverless leans well to …
-
Small, focused, asynchronous, concurrent, easy to parallelize into independent units of work
-
Infrequent or has sporadic demand, with large, unpredictable variance in scaling requirements
-
Stateless, ephemeral, without a major need for instantaneous cold start time
-
Highly dynamic in terms of changing business requirements that drive a need for accelerated developer velocity
Observability is More than Logs, Metrics & Traces
Philipp Krenn | @xeraa | xeraa.net | Elastic
CfgMgmtCamp session info | slides
Why @xeraa ? => Rotate 13 gives ‘krenn’
Observability: Foggy definition
Metrics, Tracing and Logging
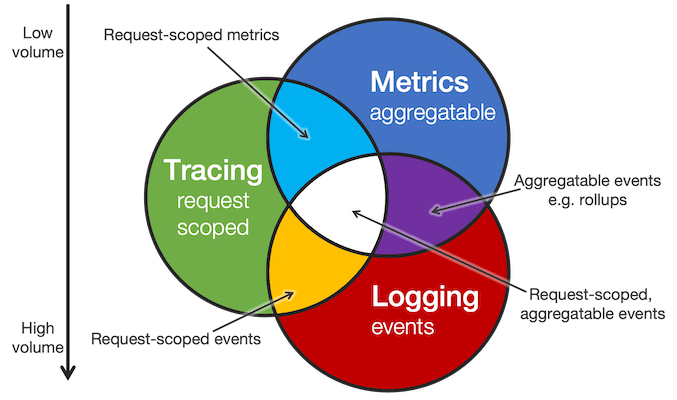 http://peter.bourgon.org/blog/2017/02/21/metrics-tracing-and-logging.html
http://peter.bourgon.org/blog/2017/02/21/metrics-tracing-and-logging.html
Observability
A system is observable if the behaviour of the entire system can be determined by only looking at its inputs and outputs. Kálmán (1961), On the General Theory of Control Systems
Known Knowns and Unknown Unknowns
It’s all about the “Known Knowns and Unknown Unknowns”.
| Knowns | Unknowns | |
|---|---|---|
| Known | Things we are aware of and understand 👁️ 🧠 | Things we are aware of but do not understand 👁️ |
| Unknown | Things we are not aware of but understand 🧠 | Things we are not aware of and do not understand |
Exposing state
Exposing state and answer:
- What is the status of my system?
- What is not working?
- Why is it not working?
Instrumentation
- Understanding without shipping new code
- Knowing your system
Not all signals are equal
- 👍 Working log in, succesful transaction, performant search, consistent shopping cart
- 👎 API uptime, error rate, DB query latency
Service Level
- Indicator (SLI) - eg. uptime
- Objective (SLO) - eg. 99%
- Agreement (SLA) - eg. <99% uptime you owe me 💸
Beyond logs, metrics & traces
Synthetic health-check => simulate user in an automated job
- (Synthetic) health checks
- Security
- Alerting
What is the goal?
- BUSINESS VALUE - always!
Conclusion
- Monitoring: Something you do to know if the system is not working
- Observability: A property of a system to know why it is not working
- Repeat after me: “You can not buy observability”*
- Observability is More than Logs, Metrics & Traces
* Though I can totally sell it to you
Terraform Configuration Without The Mess
James Nugent | @jen20 | jen20.dev | Event Store Ltd
CfgMgmtCamp session info | slides

One of the most frequent complaints about Terraform is the state that configuration gets itself into after a repository have been living for a few years. The root cause is often that teams treat Terraform as configuration instead of code, and throw basic software engineering principles out the window as a result. In this talk, we’ll look at proven patterns for writing Terraform configuration which ages well and remains an asset instead of a liability.
The Hard Thing About Kubernetes (It’s the Infrastructure!)
Paul Stack | Pulumi
Grafana-as-Code
Fully reproducible grafana dashboards with Grafonnet
Julien Pivotto | Inuits & Malcolm Holmes | Grafana Labs
This talk demonstrates technologies for automating Grafana dashboard generation and deployment.
Goal: “Get everyone see the same things”
Grafana provisioning:
- Browser UI
- ReST API
- Grafana DB
- Grafana Terraform Provider
- Grafana File Provisioning
Templating json is no fun. Happened by accident …
Jsonnet is a superset of json. Purpose generate json
:: json values are moved into the tree but not in the output Same for functions in jsonnet, declared with :: because they are never exported to json.
Generate code from a dashboard would be the “itch” to scratch.
Jsonnet

Jsonnet is a powerful data templating language for app and tool developers
- Generate config data
- Side-effect free
- Organize, simplify, unify
- Manage sprawling config
A simple extension of JSON
- Open source (Apache 2.0)
- Familiar syntax
- Reformatter, linter
- Editor & IDE integrations
- Formally specified
Grafonnet
Grafonnet, a Jsonnet library for generating Grafana dashboards. Grafonnet provides a simple way of writing Grafana dashboards. It leverages the data templating language Jsonnet. It enables you to write reusable components that you can use and reuse for multiple dashboards.
Config Mgmt for Kubernetes workloads with GitOps and Helm
Tomasz Tarczynski | Gigaset
Session description
Kubernetes provides a declarative API, so you can describe the desired state of the system. And then it is the role of the control plane to operate the cluster (make the actual state match the desired state). But we still need config mgmt for API objects to the point when they are applied to the cluster.
Helm helps to organize these configs into charts, template them, and manage releases. And GitOps lets you use a git repo as a single source of truth for the desired state of the whole system. Then all changes to this state are delivered as git commits instead of using kubectl apply or helm upgrade.
In this talk I will introduce the GitOps model for operating cloud native environments and give a short demo.
After using the GitOps model for over a year I can see that it’s still in early days compared to config management tools like puppet. I will try to show what are the strong areas and what still seems to be missing.
Notes
For configuration customization across environments and clusters, Flux comes with builtin support for Kustomize and Helm.
Kustomize

kustomize lets you customize raw, template-free YAML files for multiple purposes, leaving the original YAML untouched and usable as is.
Flagger
Flagger is a Kubernetes operator that automates the promotion of canary deployments using Istio, Linkerd, App Mesh, NGINX, Contour or Gloo routing for traffic shifting and Prometheus metrics for canary analysis. The canary analysis can be extended with webhooks for running acceptance tests, load tests or any other custom validation.
Flagger implements a control loop that gradually shifts traffic to the canary while measuring key performance indicators like HTTP requests success rate, requests average duration and pods health. Based on analysis of the KPIs a canary is promoted or aborted, and the analysis result is published to Slack or MS Teams.
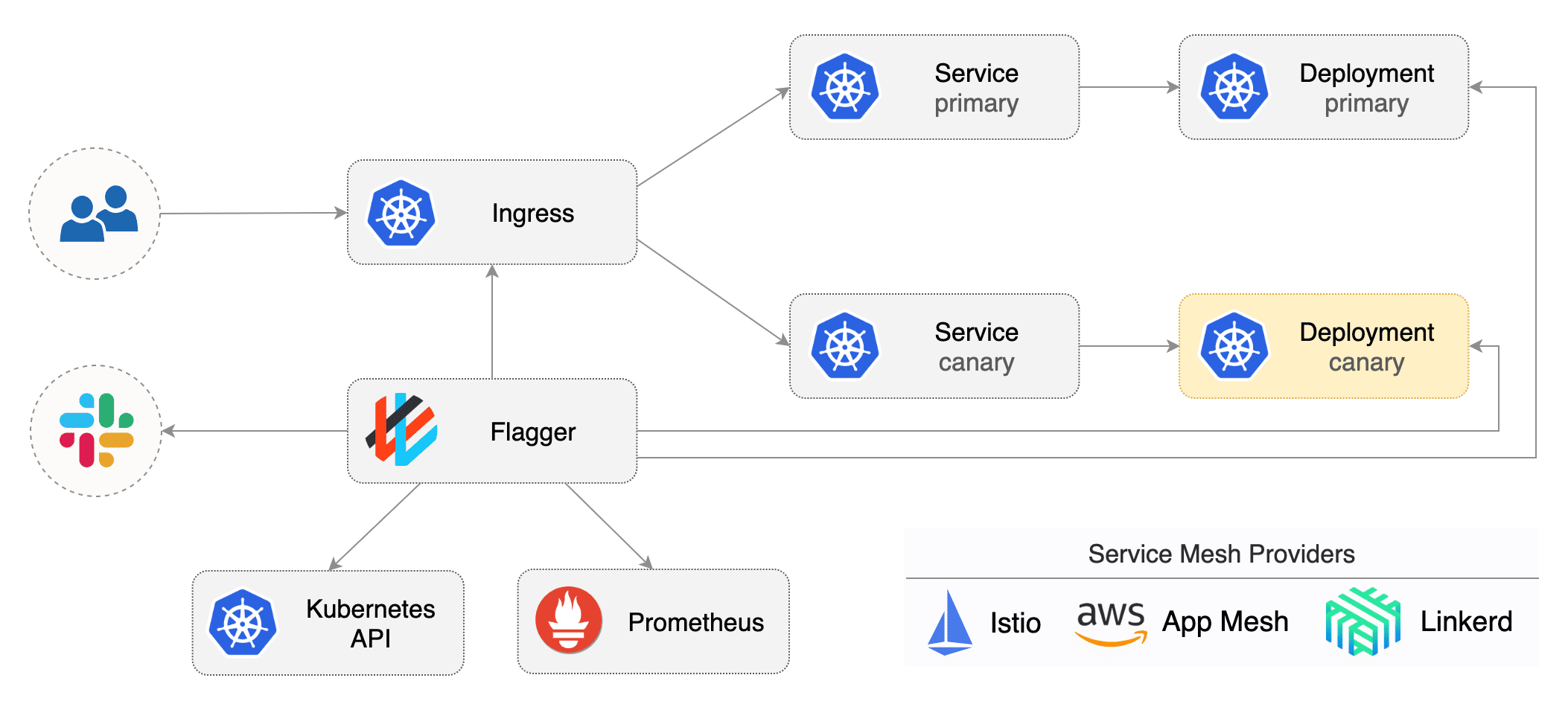
Flagger documentation can be found at docs.flagger.app
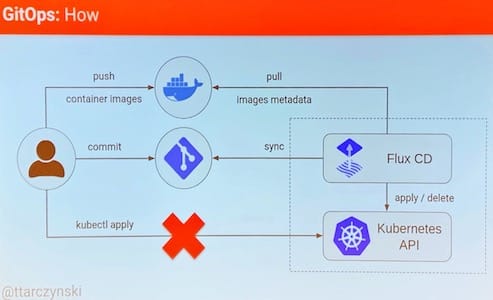
Flux, the GitOps operator for Kubernetes

Flux is a tool that automates the deployment of containers to Kubernetes. It fills the automation void that exists between building and monitoring.
Flux’s main feature is the automated synchronisation between a version control repository and a cluster. If you make any changes to your repository, those changes are automatically deployed to your cluster.
Flux generates manifests based on flux.yml and kustomize.
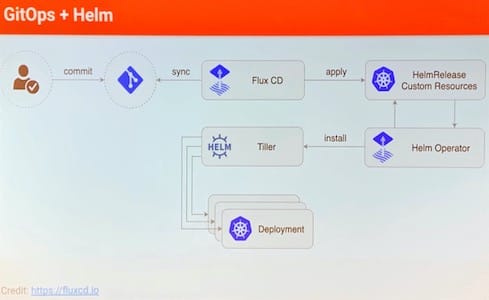
Helm, the package manager for Kubernetes

Helm helps you manage Kubernetes applications — Helm Charts help you define, install, and upgrade even the most complex Kubernetes application.
Charts are easy to create, version, share, and publish — so start using Helm and stop the copy-and-paste.
The latest version of Helm is maintained by the CNCF - in collaboration with Microsoft, Google, Bitnami and the Helm contributor community.
Your own kubernetes lab with K3S
Gratien D’haese
Have a working kubernetes on your laptop as lab environment then k3s, which is a lightweight kubernetes distribution, is your friend. K3s is also an ideal way to get acquainted with kubernetes and to test out your own containerised applications before moving to a real kubernetes cluster. This talk will introduce you to k3s and guide you how to set it and show you some practical usages with demo.
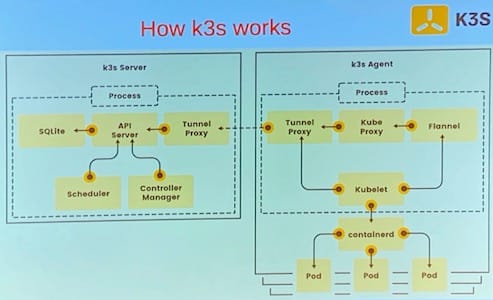
K3s introduction: github/gdha/k3s-intro
Demo with a 3 node cluster.
Add labels to your worker nodes
K3s manifest to set up local deployment /var/lib/rancher/k3s/server/manifests/
TGIK

TGIK is a weekly live video stream that we broadcast live at 1pm pacific time from the VMware Cloud Native headquarters (usually) in Bellevue, Washington all about Kubernetes.
The index contains a list of all episodes.
The official YouTube channel can be found here.
Ignite talks:
5-minute ignite talks:
- Slides in pdf format
- 20 slides (no more, no less)
- 15 seconds per slide (automated)
- Speaker has no control over the slide flow
- Impressive tool used for presenting the pdf/slides
- Lightning fast talks!
Impressive
Impressive is a program that displays presentation slides. But unlike Impress (OpenOffice.org) or other similar applications, it does so with style. Smooth alpha-blended slide transitions are provided for the sake of eye candy, but in addition to this, Impressive offers some unique tools that are really useful for presentations.
Creating presentations for Impressive is very simple: You just need to export a PDF file from your presentation software. This means that you can create slides in the application of your choice and use Impressive for displaying them. If your application does not support PDF output, you can alternatively use a set of pre-rendered image files – or you use Impressive to make a slideshow with your favorite photos.