Open Source Summit Europe 2018
Edinburgh International Conference Centre
The Future of AI is Data…In More Ways than You Think
Eric Berlow, Co-Founder, Chief Science Officer, Vibrant Data Inc.
Tim Berners-Lee
Personal data stored distributed
The What-If Tool: Code-Free Probing of Machine Learning Models

OpenMappr, explore complex networks
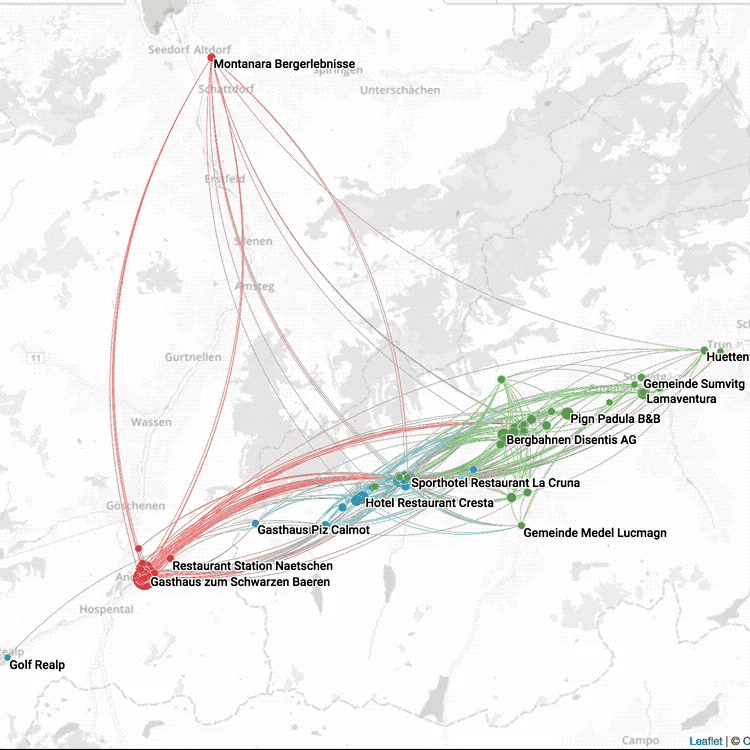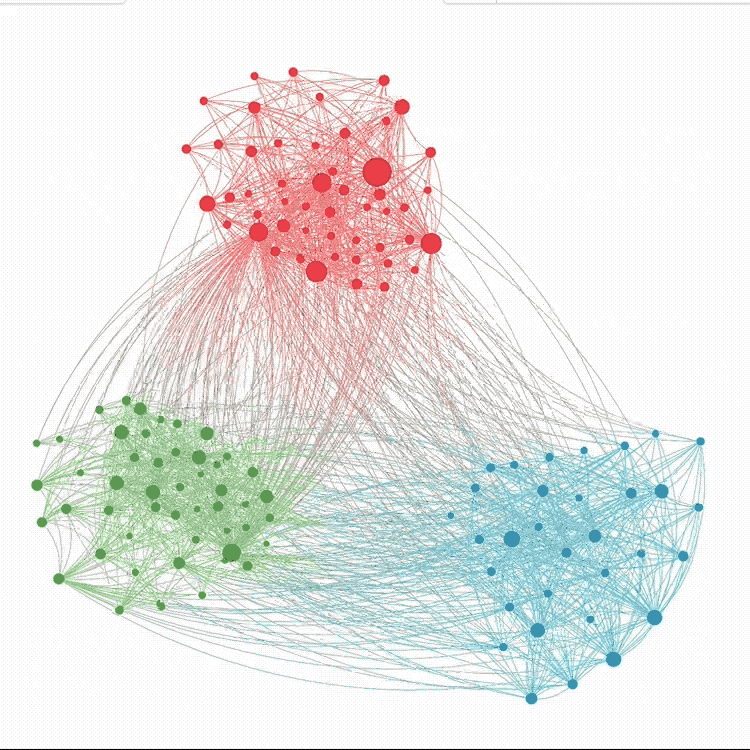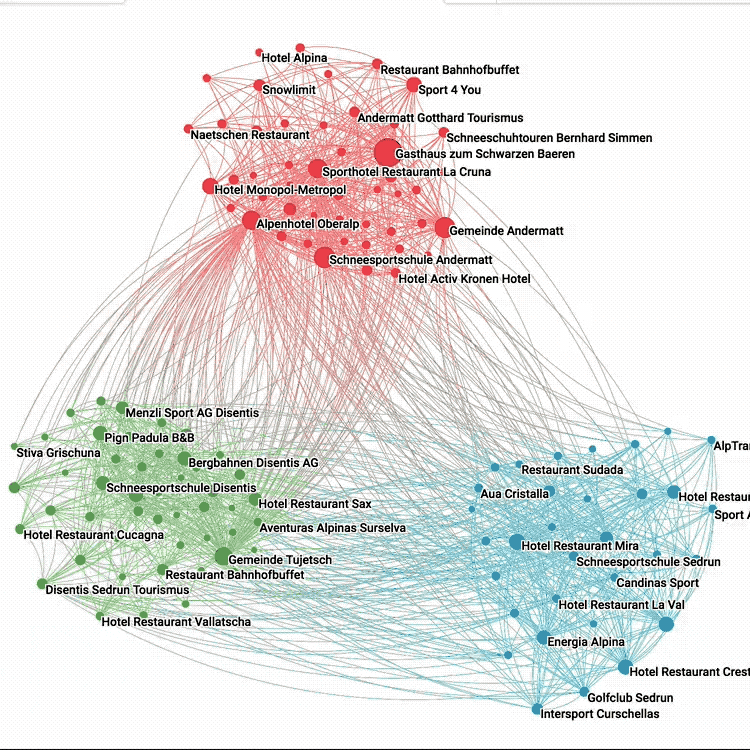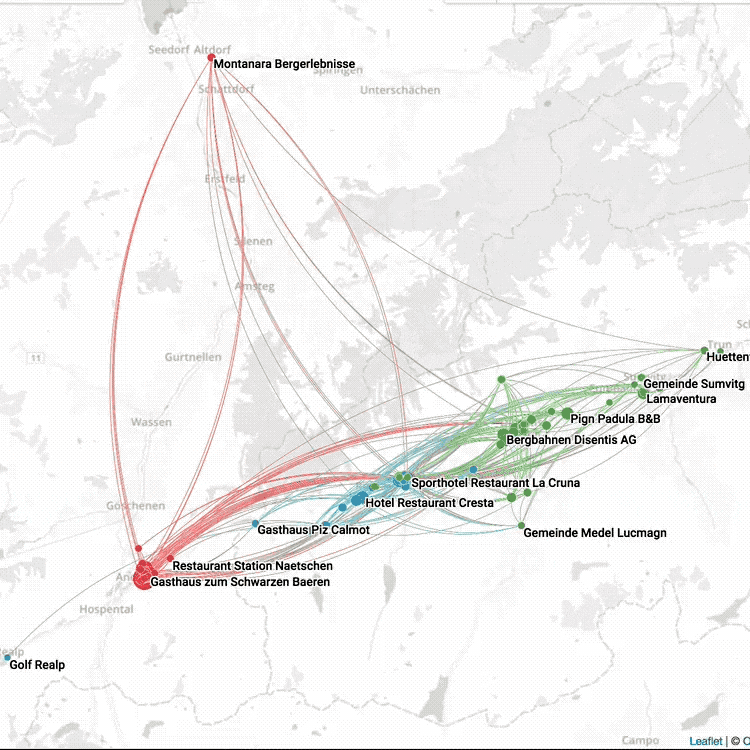
Building an Open Source Software Culture at Microsoft
Stephen Walli, Principle Program Manager, Microsoft
“Culture eats strategy for breakfast”
Creating an IoT Data Layer for Collecting, Storing, Analyzing and Reacting to Data
David G. Simmons, @davidgsIoT, InfluxData
Distributed data collections
- Data collected at multiple collection points
- Remote collections feed back-end system of record
- Distributes data collection load
- More tolerant of network outages, etc.
Data Layer Architecture
- Data collected at the edge, where it is generated
- Edge collectors also capable of analysis
- Edge collectors handle local event, etc.
- Down-sample data forwarded to backend on a network-available basis
- Lower network costs
- More fault tolerant
IoT Data Layer
- What is IoT Data?
- sensor@time - that’s time series data!
- IoT data MUST be
- Timely - ingestion rates and query efficiency is key
- Accurate - data integrity and platform reliability is important
- Actionable - data visualization, anomaly detection & alerting are essential
- IoT deployments are struglling to find efficient, scalable, data platform that meets all of these criteria
Apache Kafka - “A System Optimized for Writing”
Bernhard Hopfenmüller, ATIX AG
IRC: Fobhep, github.com/Fobhep
Interesting session giving insights into Kafka.
Toro Kernel, A Dedicated Kernel for Microservices
Matias Vara Larsen, Silicon Gears & Cesar Bernardini, Barracuda

Toro is a simple kernel that allows microservices to run efficiently in VMs thus leveraging the strong isolation VMs provide.
What is it?
Toro is a simple kernel that provides a dedicated API to develop microservices. We propose two kinds of sockets to build microservices: blocking and non-blocking. Blocking sockets are good for intensive-IO microservices whereas non-blocking sockets are good for microservices that can serve a request without blocking. When a microservice executes in Toro, it runs alone in the system thus leveraging on the VM’s resources.
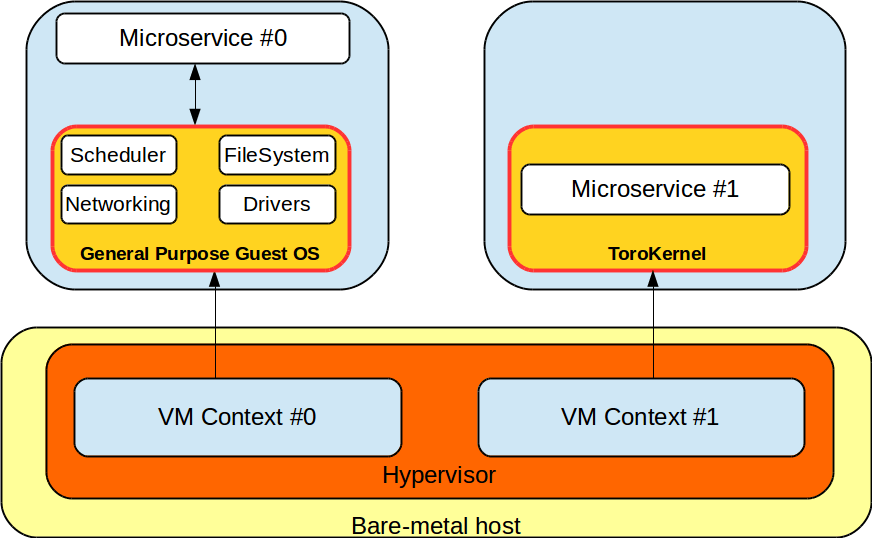
A dedicated kernel for multi-threading applications.
How it works?
Toro is a set of libraries that compile within the user application, i.e., the microservice. The user can choose which components should be included, .e.g, drivers, filesystems, etc. This results in a binary that can run on top of modern hypervisors like KVM, Xen or VirtualBox. Once the kernel has been initialized, the microservice starts to execute. The microservice and the kernel execute at the most privileged level and share the memory space, i.e., flat memory model. In this sense, Toro only supports threads and does not use paging.
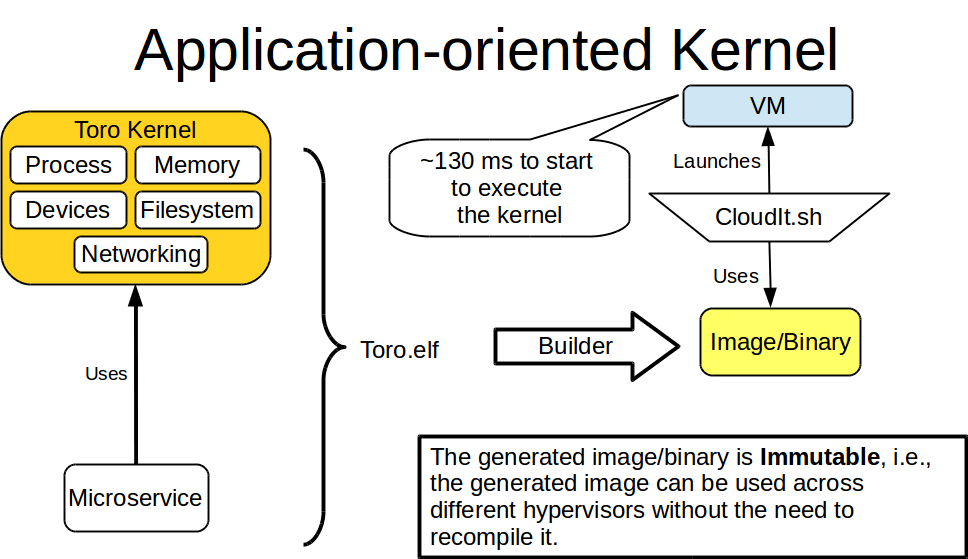
- Blogspot
- Torokernel.io
- How to Compile and Run an Example in Toro · MatiasVara/torokernel Wiki · GitHub
Summary
- Toro is a kernel dedicated to run microservices
- Toro provides a dedicated API to specify microservices
- Toro design is improved in four main points:
- Booting time and building time
- communication to the kernel
- memory access
- networking

Talked to César Bernardini (mesarpe@gmail.com) from Argentina.
Connected César to Alex Ellis.
Introduction to Natural Language Processing with Python
Barbara Fusinska, barbarafusinska.com, Google
Reuters dataset
- Reuters-21578 dataset
- Documents assembled and indexed with categories
- Appeared in the Reuters newswire and made public
Bag of words
Documents:
- John likes to watch movies. Mary likes to watch movies too.
- John also likes to watch football games.
Vocabulary:
[also, and, both, football, …]
Stemming
Reduce the words to their root form:
- likes => like
- movies => movie
- watched => watch
Vocabulary:
[also, football, games, john, like, mary, … ]
Machine learning: Training & Validation

Python Natural Language Toolkit (NLTK)
- Lexical Analysis (tokenizing)
- Part of speech tagger
- Namedentity recognition
- Stemmers
“An amazing library to play with natural language”
scikit-learn: Machine Learning in Python
- Classification, Regression, Clustering
- Dimensionality reduction
- Model selection
- Preprocessing
Conclusions
- Heavy on data and preparation and feature generation
- Vocabulary requires proper design
- Sparse vectoor representation
- Discarding word order may lose context
- Stop words may mislead the meaning
- Word stemming may limit information
Cloud-init
Chad Smith & Scott Moser, Canonical
- cloud-init.io
- read the docs
- IRC: Freenode #cloud-init, smoser, blackboxsw
- Mailing list: cloud-init@lists.launchpad.net