20 years of FOSDEM

FOSDEM is a free event for software developers to meet, share ideas and collaborate. Every year, thousands of developers of free and open source software from all over the world gather at the event in Brussels.
![]()
Fundamental Technologies We Need to Work on for Cloud-Native Networking
Magnus Karlsson | Intel
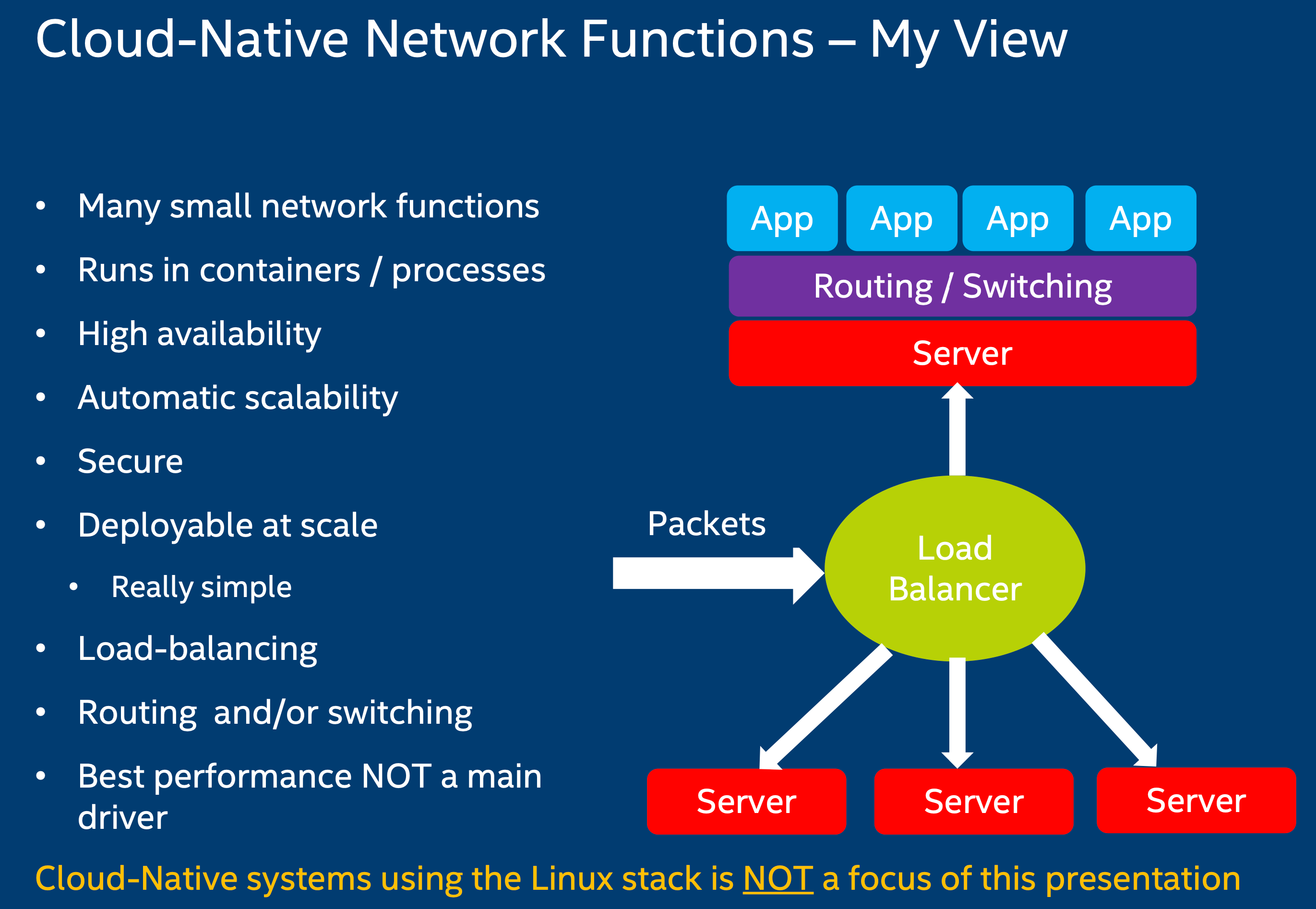
“Good is good enough”
Very pragmatic quote, no need to strive for perfection …
Doomed are the dinosaurs!
Dealing with diversity by utilizing the versatility of Ansible and open source
David Heijkamp | Naturalis
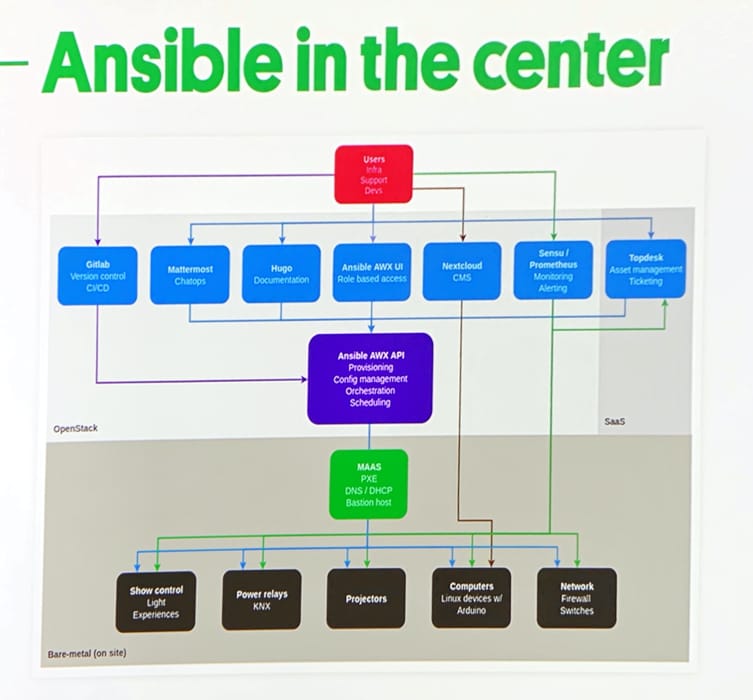
“Ansible wel suited for an imperfect environment.”
Code samples on gitlab
Compliance management with OpenSCAP and Ansible
Using OpenSCAP and Ansible for compliance management of large computing environments
Amit Upadhye | Red Hat
OpenSCAP


In the ever-changing world of computer security where new vulnerabilities are being discovered and patched every day, enforcing security compliance must be a continuous process. It also needs to include a way to make adjustments to policies, as well as periodic assessment and risk monitoring. The OpenSCAP ecosystem provides tools and customizable policies for a quick, cost-effective and flexible implementation of such a process.
Security compliance is a state where computer systems are in line with a specific security policy.
Security Content Automation Protocol (SCAP) is a multi-purpose framework of specifications that supports automated configuration, vulnerability and patch checking, technical control compliance activities, and security measurement.
OpenSCAP has received a NIST certification for its support of SCAP 1.2.

oscap NIS-certified command line scanner.
OpenSCAP with Ansible

To assist with integrating configuration compliance into your existing Ansible workflow, OpenSCAP generates remediations for use with Ansible. The remediations are generated in a form of Ansible playbooks, either based on profiles or based on scan results.
A playbook based on a SCAP Security Guide (SSG) profile contains fixes for all rules, and the system is remediated according to the profile regardless of the state of the machine. On the other hand, playbooks based on scan results contain only fixes for rules that failed during an evaluation.
Tasks contained in playbooks are tagged with the same metadata as rules in an Extensible Configuration Checklist Description Format (XCCDF) file. These tags refer to rule ID, strategy, complexity, disruption, and references, and they can be used to filter the tasks to apply.
Text form the paragraph above is excerpt from Red Hat 7.7 Using OpenSCAP with Ansible
Introduction to Ansible collections
Ansible collections, the future of Ansible content delivery
Ganesh Nalawade, Abhijeet Kasurde | Red Hat
A Closer Look at Collections
An Ansible Content Collection can be described as a package format for Ansible content:

This format has a simple, predictable data structure, with a straightforward definition:
- docs/: local documentation for the collection
- galaxy.yml: source data for the MANIFEST.json that will be part of the collection package
- playbooks/: playbooks reside here
- tasks/: this holds ‘task list files’ for include_tasks/import_tasks usage
- plugins/: all ansible plugins and modules go here, each in its own subdir
- modules/: ansible modules
- lookups/: lookup plugins
- filters/: Jinja2 filter plugins
- connection/: connection plugins required if not using default
- roles/: directory for ansible roles
- tests/: tests for the collection’s content
Interacting with Collections
In addition to downloading collections through the browser, the ansible-galaxy command line utility has been updated to manage collections, providing much of the same functionality as has always been present to manage, create and consume roles. For example, ansible-galaxy collection init can be used to create a starting point for a new user created collection.
Where to Find Collections
With the launch of Red Hat Ansible Automation Platform, Automation Hub will be the source for certified collections. Additionally, collections creators can also package and distribute content on Ansible Galaxy. Ultimately, it is up to the creator to decide the delivery mechanism for their content, with Automation Hub being the only source for Red Hat Certified Collections. Find more information regarding obtaining certified collections from Automation Hub here.
Why Collections?
- Multiple roles with dependencies
- Maintain version dependencies across roles and Ansible versions
- Difficult distribution of non-role content
- Plugin/role name collisions
- Difficult to do code-sharing for most plugins
Links
- Red Hat Ansible blog “The Inside Playbook” Getting started with Ansible content collections also used as source for some of the paragraphs above.
- Ansible documentation: Using collections
Designing for Failure ‘rm -rf /’
Fault Injection, Circuit Breakers and Fast Recovery
Walter Heck
Design for failure?
Initial reaction is counter intuitive. “We’re building something that works …”
Given infinite time, falure is inevitable (You might just get lucky that it’s not your problem)
The Berkeley/Stanford Recovery-Oriented Computing (ROC) project
Recovery-Oriented Computing Overview
ROC Research Areas:
- Isolation and Redundancy
- System-wide support for Undo
- Integrated Diagnostic Support
- Online Verification of Recovery Mechanisms
- Design for high modularity, measurability, and restartability
- Dependability/Availability Benchmarking
Designing for failure
There will be always be one single point of failure even it is the entire system
- Exception handling
- Fault tolerance and isolation
- Fall-backs and degraded experiences
- Auto-scaling
- Redundancy
S3: 11 nines durability but only 4 nines availability.
“Hope is not a Strategy”, Google SRE motto
The question is how much is it worth to not not fail
“Zero downtime” is an unreasonable goal
Personally I think that seems questionable, firstly you can always set the goal, secondly do not confuse downtime with availability which includes external factors.
Dealing with Failure, the Infrastructure Domain
- Disaster Recovery
- High Availability
- Fault Tolerance
- Redundancy
- Triple Modular Redundancy
- Forward Eror Correction
- Checkpointing
- Byzantine Fault-Tolerance
- Resilience or Recoverability
- Readiness and Liveness probes - Determine if an application is ready to serve trafiic and if it is able to handle incoming requests
Nice read on the subject: Fault Tolerance Is Not High Availability
Tooling
- Corosync, the Corosync Cluster Engine is a Group Communication System with additional features for implementing high availability within applications.
- Pacemaker - Cluster Resource Manager, Pacemaker is an Open Source, High Availability resource manager suitable for both small and large clusters (uses Corosync).
- MySQL Cluster CGE, Galera Cluster for MySQL, CockroachDB etc.
- Amazon Route 53 failover policy, Route 53 is a scalable and highly available Domain Name System service or alternatives like GoDaddy, Google Cloud DNS, CloudFlare etc.
Dealing with Failure, the Software Domain
- Circuit Breaker design pattern
- Martin Fownley - CircuitBreaker
- Netflix Hystrix, Latency and Fault Tolerance for Distributed Systems. Note: Maintenace mode
- Checkpoint
- Rollback
- Roll-Forward
- Return to Reference Point
- Resilience4j, java8
- Resilient-task, php
- Istio and Service Mesh

InfoQ: Towards Successful Resilient Software Design
O’Reilly Patterns for Fault Tolerant Software by Robert S. Hanmer (2007)
Ephemeral Environments For Developers In Kubernetes
Jeff Knurek | @knurekit | Trave Audience
Local Kubernetes environments:
- Minikube (Kubernetes)
- Docker Desktop (Docker)
- microK8s (Canonical)
- kind Kubernetes in Docker
- k3d k3s in Docker (Rancher)
Armador
Go app for building dev environments in kubernetes. Github/travelaudience/armador
![]()
A tool for creating ephemeral test environments in Kubernetes.
The best analogy for what Armador provides would be to compare it to Docker Compose, but for Kubernetes.
Helm is the building block that Armador is based upon. The idea is that a small configuration file is provided for core dependencies for the environment, and then in each chart that needs another chart to be built, that gets referenced inside a armador.yaml file in the chart.
Why not use an “umbrella” helm chart?
The limitation with umbrella charts is that the individual services don’t have their own lifecycle. The other problem is that the developer of one service doesn’t know all the other dependencies another service has. So they are not able to build their own umbrella charts on demand.
Example applications
github.com/dockersamples/example-voting-app github.com/travelaudience/armador/tree/master/docs/example

Other tools
- Acyl is a server and CLI utility for creating dynamic testing environments on demand in Kubernetes, triggered by GitHub Pull Requests (DSC blog article).
- Tilt manages local development instances for teams that deploy to Kubernetes (Github/WindmillEng).
- Helmfile, deploy Kubernetes Helm Charts
- Garden Garden is a developer tool that automates your workflows and makes developing and testing Kubernetes applications faster and easier than ever Github/Garden-io.
- Skaffold is a command line tool that facilitates continuous development for Kubernetes applications Github/GoogleContainerTools.
- Velero (formerly Heptio Ark) is an open source tool to safely backup and restore, perform disaster recovery, and migrate Kubernetes cluster resources and persistent volumes Github/vmware-tanzu.

How Containers and Kubernetes re-defined the GNU/Linux Operating System
A Greybeard’s Worst Nightmare
Daniel Riek | Red Hat
Greybeards fight Balrogs. They hate systemd. They fork distributions.
Infrastructure as a Cloud:

The (Modern) Cloud:

The Cost of Cloud
- Dominated by proprietary public cloud offerings
- Lock-in with black-box-services
- Data Gravity
- Growing life cycle dependency
- High OPEX when scaled
- Reproducibility?
- ‘GNU / Linux Distribution as a Service’ - Without the contributions back.
- ‘Strip-mining’ FOSS and SW innovation in general.
- Move towards service aggregation, vertical integration.
Traditional Distro vs App-Centricity
Diminishing Returns at Growing Complexity
Traditional binary software distribution great for foundational platform components…
But:
- Modern software stacks have become too complex to be mapped into a common, monolithic namespace.
- As a developer, I have to go to native packaging (e.g. npm) anyways because the distribution does only provide a small part of what I need to build my application.
- Slow delivering new versions to app developers.
- The higher in the stack, the bigger the issue.
- Re-packaging, frozen binary distribution offers little value for the App developer.
- Upstream binary/bytecode formats sufficient, they compile their software anyways, lock-in for hybrid environments.
- Testing is more valid if done with the actual application, using it.
- Updating of services in production at the component level is too volatile.
Liberation? - Containers
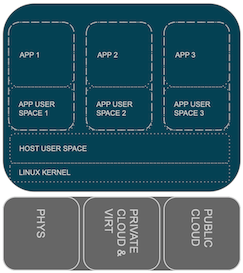
Expanding use of containers, from VServer over LXC to OCI
- Separate the application runtimes from system runtime.
- Like chroot but with an epstein drive.
- Multi-instance, multi-version environment with possible multi-tenancy: each service has it’s own binary runtime.
- Light-weight - at the end, it’s just linux processes separated by kernel features: CGroups, Namespaces, SELinux
Good bye Dependency Hell
If you are running Fedora, try:
# sudo dnf -y install toolbox
# toolbox enter
Enter: The Container Revolution
OCI Containers provide the package format for Application-Centric IT

- Aggregate packaging deployed into containers.
- Initiated by the project previously known as ‘Docker’. Now implemented by native stack with CRI-O, Podman, and Buildah.
- Combine existing Linux Container technology with Tar + overlays -> Unicorns
- Frozen binary distribution, reproducible builds.
- Build once, distribute binary across multiple Linux servers.
- Metadata, signatures.
- Management of installed artifacts, updates.
- Transport for a curated content from a trusted source.
- Fully predictable stack behaviour, life cycle, lightweight.
- Implements an early-binding model for deploying applications packaged by a developer. CI/CD friendly.
The best of both worlds. Encapsulates stack complexity and provides a relatively stable interface.
Multi Container Apps
In reality, most applications consist of multiple containerized services.
- Ideal container is only a single binary.
- Applications are aggregated from multiple containerized services.
- Ideal for cloud native applications. Hybrid model for existing apps.
- From multi-tier applications to micro services.
- Static linking or dynamic orchestration.
Great to solve dependency hell, but how to make sure my frontend knows which database to talk to?
Kubernetes: The Cluster Is The Computer
By default, everything is a cluster
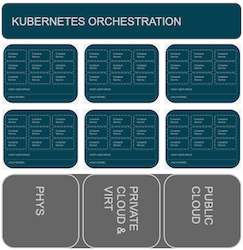
- Kubernetes manages containerized services across a cluster of Linux nodes.
- Application definition model, describing the relationship between services in abstraction from the individual node.
- Abstraction from the underlying infrastructure: compute, network, storage.
- Same application definition remains valid across changing infrastructure.
- Whole stack artifacts move across dev/test/ops unmodified.
- Scale-out capabilities and HA are commoditized into the standard orchestration.
- Often built around immutable infrastructure models.
Operators: Standardized Operational Model
PROBLEM: How to manage the operation of complex, multi-container apps?
SOLUTION: Kubernetes Operators
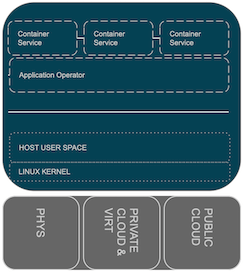
- Active component implementing the operational logic for a specific application.
- Capability Levels
- Basic Install
- Seamless Upgrades
- Full Lifecycle
- Deep Insights
- Auto Pilot
Federate the encapsulation of operational Excellence. Future: AI Ops
OperatorHub, not recommended by everyone.
Conclusions
- GNU / Linux’ historic role was to break vertical integration and provide a common platform for an open ecosystem.
- The cloud has changed IT, driving efficiency across elasticity, developer velocity and encapsulated operational excellence.
- The downside of cloud is concentration, vertical integration and lock-in.
- Containers and Kubernetes offer the opportunity to create an open alternative platform.
- Kubernetes and operators provide the base for a standardized operational model that can competitive to the cloud providers’ operational expertise.
- It can enable a heterogeneous ecosystem of services at the same level of service abstraction as the public Clouds.
- FOSS needs to go beyond software access and democratize operations.
Fixing the Kubernetes clusterfuck
Understanding security from the kernel up
Kris Nova | Sysdig
TIL: Loris Degioanni, the co-creator of Wireshark is also founder of Sysdig.
![]()
Falco, the open source cloud-native runtime security project, is the defacto Kubernetes threat detection engine. Falco detects unexpected application behavior and alerts on threats at runtime.
Falco efficiently leverages Extended Berkeley Packet Filter (eBPF), a secure mechanism, to capture system calls and gain deep visibility. By adding Kubernetes application context and Kubernetes API audit events, teams can understand who did what.
Falco is the first runtime security project to join CNCF Incubating stage. sudo insmod falco …
Open Policy Agent (OPA, pronounced “oh-pa”) is an open source, general-purpose policy engine that unifies policy enforcement across the stack. OPA provides a high-level declarative language that let’s you specify policy as code and simple APIs to offload policy decision-making from your software. You can use OPA to enforce policies in microservices, Kubernetes, CI/CD pipelines, API gateways, and more.
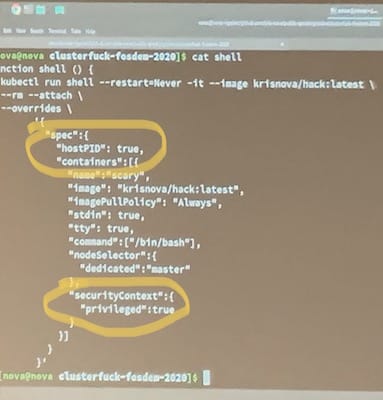 hostPID en privileged should not be set here!
hostPID en privileged should not be set here!
Address Space Isolation in the Linux Kernel
Mike Rapoport and James Bottomley
Interesting stuff, but takes time to really read and understand it.
Infrastructure testing, it’s a real thing
Paul Stack | @stack72 | paul@pulumi.com | Pulumi
2007 Martin Fowler: Mocks Aren’t Stubs
Pulumi is an open source infrastructure as code tool for creating, deploying, and managing cloud infrastructure. Pulumi works with traditional infrastructure like VMs, networks, and databases, in addition to modern architectures, including containers, Kubernetes clusters, and serverless functions. Pulumi supports dozens of public, private, and hybrid cloud service providers.
Is Pulumi an alternative for Terraform? Or competition? I do see advantages like being able to use your own programming language to create the workflows. Blow is he comparison by Pulumi with other solutions.
Pulumi vs. Other Solutions
Pulumi is a cloud-native infrastructure as code project. It lets you provision and manage resources across many clouds—AWS, Azure, Google Cloud, Kubernetes, OpenStack—using your favorite language. It works great for a wide range of cloud infrastructures and applications, including containers, virtual machines, databases, cloud services, and serverless.
Because of this broad array of supported scenarios, there are many tools that overlap with Pulumi’s capabilities. Many of these are complementary and can be used together, whereas some are “either or” decisions.
Here are several useful comparisons that will help you understand Pulumi’s place in the cloud tooling ecosystem:
- Hashicorp Terraform
- Cloud Templates (AWS CloudFormation, Azure RM, etc.)
- AWS CDK and Troposphere
- Cloud SDKs (AWS Boto, etc.)
- Serverless Framework
- Kubernetes YAML and DSLs
- Chef, Puppet, Ansible, Salt, etc.
- Custom Solutions
Mgmt Config: Autonomous Datacentres
Real-time, autonomous, automation
James Shubin | @purpleidea | purpleidea.com

mgmt, next generation distributed, event-driven, parallel config management!

Mgmt is a real-time automation tool. It is familiar to existing configuration management software, but is drastically more powerful as it can allow you to build real-time, closed-loop feedback systems, in a very safe way, and with a surprisingly small amout of our mcl code. For example, the following code will ensure that your file server is set to read-only when it’s friday.
We are nearing a 0.1 version, James is very positive about it (when not). I see possibilities but also challenges. This still seems to be a one-man show.
Show in a ‘literal’ sense as well, he starts his presentation with some fire-tricks 😉 Never a dull presentation with James …
Note to self: use ‘watch’ more often.
Gofish - a Go library for Redfish and Swordfish
Gofish is a Golang library for interacting with Redfish and Swordfish enabled devices.

Gofish is a Golang library for interacting with Redfish and Swordfish enabled devices. This presentation will give an overview of the current state of the library and how it can be used to manage compute and storage resources using a common, standard API.
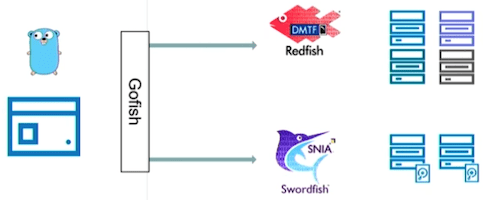
- Gofish - Redfish and Swordfish client library (source)
- Redfish Standard
- Swordfish Standard
- bmc-toolbox
Redfish testing
Use Redfish simulator to test/dev against.